
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
Tags
- 복합대입연산자
- 2차원배열
- 팩토리얼
- switch문
- #Java
- #이차원배열
- 별찍기
- 삼항 연산자
- 연산자
- 논리연산자
- else if문
- 이진수
- 피보나치수열
- #완전수구하기
- 비교연산자
- 증감연산자
- if문
- 알고리즘
- 로또 프로그램
- #알고리즘
- java조건문
- JAVA기초
- java
- switch-case문
- plusgame
- for문 369게임
- 데이터타입
- #java_festival
- 소인수분해
- 변수의특징
Archives
- Today
- Total
숭어 개발 블로그
[딥러닝]_손글씨 이미지데이터 분류 본문
# 목표
- 0 ~ 9 까지의 손글씨 이미지 데이터를 분류하는 모델을 만들어보자!
# keras 에서 지원하는 딥러닝 학습용 손글씨 데이터 임포트
# 국립표준기술원 (NIST)의 데이터셋을 수정해서 만든 학습데이터
from tensorflow.keras.datasets import mnist
# 이미지라는 2차원데이터를 다루기 떄문에 shape 의 형태가 3칸이 나오게됨
# (데이터의수, 가로픽셀수, 세로픽셀수)

print (X_train.shape)
print (y_train.shape)
print (X_test.shape)
print (y_test.shape)

plt.imshow(X_train[59999],cmap='gray');
# imshow : 이미지 데이터를 그림으로 출력해주는 명령
# cmap : 출력되는 이미지의 컬러를 지정할 수 있는 명령
(gray : 흑백이미지)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# keras 에서 지원하는 딥러닝 학습용 손글씨 데이터 임포트
# 국립표준기술원 (NIST)의 데이터셋을 수정해서 만든 학습데이터
from tensorflow.keras.datasets import mnist
data = mnist.load_data()
len(data)
(X_train,y_train), (X_test,y_test) = data
# 이미지라는 2차원데이터를 다루기 떄문에 shape 의 형태가 3칸이 나오게됨
# (데이터의수, 가로픽셀수, 세로픽셀수)
print (X_train.shape)
print (y_train.shape)
print (X_test.shape)
print (y_test.shape)
y_train
plt.imshow(X_train[59999],cmap='gray');
# imshow : 이미지 데이터를 그림으로 출력해주는 명령
# cmap : 출력되는 이미지의 컬러를 지정할 수 있느 명령(gray : 흑백이미지)
# 정답데이터를 원핫인코딩 하는 이유
- 신경망 출력층에서 각 레이블 값들에 대한 확률 정보와 비교하여 오차를 구하기 위하여
- 신경망 내부의 기본 모델이 선형모델이고 최적의 w,b값을 구하기위해서 오차를 점점 줄여나가는 방식으로 모델이 학습하게됨
- 신경망이 출력한 결과(확률값) 와 실제 정답의 scale(0~1)을 같게 맞춰줘서 비교를 용이하게 만들어주기 위함!
- 다중분류 에서는 항상 정답을 '원핫 인코딩' 시켜주기~!
# tensorflow 지원해주는 원핫 인코딩 명령(배열(array)로 변환이됨)
# pandas의 원핫 인코딩은 DataFrame 형태로 변환

# tensorflow 지원해주는 원핫 인코딩 명령(배열(array)로 변환이됨)
# pandas의 원핫 인코딩은 DataFrame 형태로 변환
from tensorflow.keras.utils import to_categorical
y_train_one_hot = to_categorical(y_train)
y_test_one_hot = to_categorical(y_test)
y_train_one_hot
y_test_one_hot
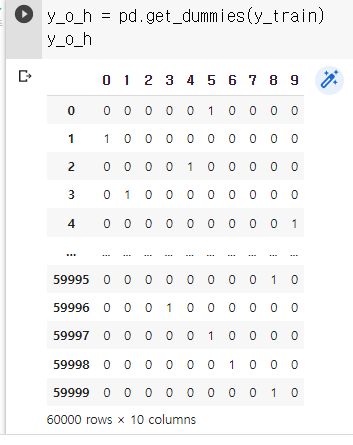
y_o_h = pd.get_dummies(y_train)
y_o_h
y_train_one_hot.shape


# 신경망 구조 설계
# 입력되는 특성의수 : 784
# 출력층의 뉴런의 개수 :10개
# 출력층의 활성화 함수 : softmax
# 학습시 사용되는 손실함수(loss) :categorical_crossentropy >> 다중분류시 사용되는 손실함수

from tensorflow.keras import Sequential # 신경망의뼈대를 설정해주는 함수
from tensorflow.keras.layers import Dense # 뉴런의 묶음을 만들어주는 함수
from pandas.core.strings.accessor import StringMethods
from os import access
# 1.신경망 구조설계
model = Sequential()
# 입력층(input_dim) + 중간층 1개(Dense)
# input_dim : 입력되는 데이터의 특성 수
# activation : 활성화 함수 설정(들어온 자극(data)에 대한 응답 여부를 결정 하는 함수)
model.add(Dense(700,input_dim=784, activation = 'sigmoid'))
#중간층
model.add(Dense(350, activation='sigmoid')) # 하나의 층
model.add(Dense(200, activation='sigmoid'))
model.add(Dense(100, activation='sigmoid')) # 하나의 층
model.add(Dense(50, activation='sigmoid'))
#출력층
#출력층은 회귀(linear, 디폴트), 2진분류(sigmoid), 다중분류에 따라 사용하는 활성화 함수가 달라진다!
model.add(Dense(10,activation='softmax'))
model.summary()
# 2.학습/평가 방법 설정
model.compile(loss="categorical_crossentropy",
optimizer="SGD", # 최적화 함수 : 경사강법의 방식을 설정해주는 함수
metrics=['acc']
)
h= model.fit(X_train,y_train_one_hot, epochs=100)



# 학습 도중에 과대적합을 확인하기 위해 train 데이터에서 검증셋을 분리시켜 학습시 같이 결과를 출력해보자

# 무조건 train, test만 나눠주는게 아니라 데이터를 일정한 비율로 나눠주는 함수
from sklearn.model_selection import train_test_split
X_train,X_val,y_train_one_hot,y_val_one_hot = train_test_split(X_train, y_train_one_hot,
random_state=3)
print(X_train.shape)
print(X_val.shape)
print(y_train_one_hot.shape)
print(y_val_one_hot.shape)
from pandas.core.strings.accessor import StringMethods
from os import access
# 1.신경망 구조설계
model1 = Sequential()
# 입력층(input_dim) + 중간층 1개(Dense)
# input_dim : 입력되는 데이터의 특성 수
# activation : 활성화 함수 설정(들어온 자극(data)에 대한 응답 여부를 결정 하는 함수)
model1.add(Dense(700,input_dim=784, activation = 'sigmoid'))
#중간층
model.add(Dense(350, activation='sigmoid')) # 하나의 층
model1.add(Dense(100, activation='sigmoid')) # 하나의 층
model1.add(Dense(50, activation='sigmoid'))
#출력층
#출력층은 회귀(linear, 디폴트), 2진분류(sigmoid), 다중분류에 따라 사용하는 활성화 함수가 달라진다!
model1.add(Dense(10,activation='softmax'))
model1.summary()


예측값 : 숫자 7
정답 : 숫자 7

모델 정확도 : 0.9871....

'Deep Learning' 카테고리의 다른 글
| [딥러닝] keras 맛보기 (폐암 환자 생존 예측) (1) | 2022.10.05 |
|---|---|
| [딥러닝] Perceptron( 퍼셉트론 ) 이란? (0) | 2022.09.27 |
| [딥러닝] Deep Learning이란? (0) | 2022.09.27 |
'Deep Learning' Related Articles
more



Comments